オンライン英会話が続かないので、英語を話せる友達を自作した(Python × OpenAI)
目次を開く
この記事は Zenn でも公開しています。
https://zenn.dev/netakiryosuke/articles/39caffd6439147
はじめに
エンジニア、英語からは逃げられません。
私は新卒 1 年目のバックエンドエンジニアで、Java や AWS を触っています。
毎日のように英語のドキュメントやエラーメッセージに向き合っています。
エラーメッセージ。
最新の技術記事。
プログラミング言語そのもの。
だいたい英語です。
だから英語を勉強したい。でも、オンライン英会話は続きませんでした。
- 予約が面倒
- 時間を空けるのが面倒
- 予習も面倒
流行りの AI 英会話アプリも試しました。でも、
「スマホを開く→アプリ起動→録音ボタンを押す」
この 3 ステップすら、面倒くさがりな自分には重かったのです。
英語を話すこと自体が嫌なのではなく、
始めるまでが面倒だった。
そこで思いました。
英語を"開くもの"ではなく、"そこにいるもの"にできないか?
- 毎回アプリを探さなくていい
- スマホを構えなくていい
- 思いついたときに、そのまま話せる
そんな存在がデスクトップに常駐していたら、英語はもう少し自然になるのではないか。
というわけで、英語を話せる友達を自作しました(飛躍)
作ったもの
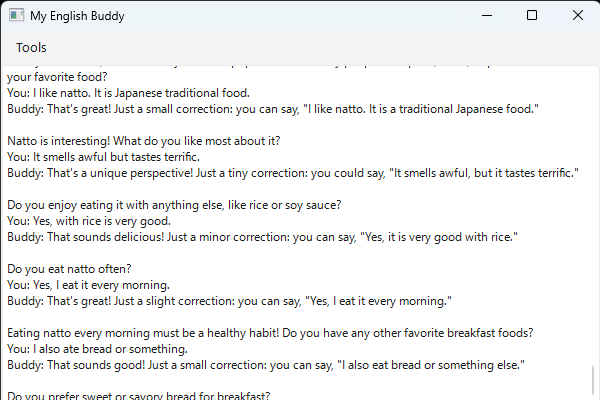
白い画面に、会話ログだけ (友達とは)
特徴:
- デスクトップアプリ
- 起動後、名前を呼ぶことで会話開始
- UI は会話ログのみ
- すべて Python で記述
技術スタック:
- STT: OpenAI Whisper API / FastWhisper(ローカル切替可)
- Chat: OpenAI GPT-4o-mini
- TTS: OpenAI TTS API
- UI: PySide6
どうやって英語を話せるようにしているのか
やっていることはシンプルです。
- 私の声をテキストに変換する(STT:Speech-to-Text)
- AI に返答を生成してもらう(LLM)
- その返答を音声に変換する(TTS:Text-to-Speech)
これだけです。
構成図:
マイク → STT → LLM → TTS → スピーカー
↓ ↓ ↓
テキスト 応答文 音声データ
音声認識でテキスト化し、LLM で応答を生成、TTS で音声化 いわゆる Input → STT → LLM → TTS → Output のパイプライン構成です。
「会話」を要素分解すると、意外とシンプルなんです。
アーキテクチャ設計
せっかくなので設計も意識してみました。
DDD のレイヤードアーキテクチャを参考に、
一部クリーンアーキテクチャの考え方も取り入れています。
ディレクトリ構成:
app/
├── domain/ # ドメイン層(ビジネスロジックの中核)
│ ├── entity/ # エンティティ
│ └── vo/ # 値オブジェクト
├── application/ # アプリケーション層(ユースケース)
│ ├── conversation_service.py
│ ├── conversation_runner.py
│ └── port/ # インターフェース定義
├── infrastructure/ # インフラ層(外部サービスとの接続)
│ ├── openai/ # OpenAI API実装
│ ├── local/ # FastWhisper実装
│ └── audio/ # マイク・スピーカー
├── presentation/ # プレゼンテーション層(UI)
│ └── main_window.py
└── utils/ # 共通ユーティリティ
依存関係の制御
presentation → application → domain
↑
infrastructure
- ドメイン層は他に依存しない(純粋なビジネスロジック)
- インフラ層の変更(OpenAI → 別の API)が容易
- テストしやすい
Portパターンの採用
一般的なレイヤードアーキテクチャでは domain/repository にインターフェースを配置しますが、このアプリでは application/port に配置しています。
これにより、Repository 以外の外部サービス(STT/TTS/Chat)も 同じパターンで管理できるようになります。
application/port/ にインターフェースを定義:
# application/port/speech_to_text.py
from typing import Protocol
import numpy as np
class SpeechToText(Protocol):
"""音声→テキスト変換のインターフェース"""
def transcribe(self, audio: np.ndarray) -> str:
"""音声データをテキストに変換"""
...実装は infrastructure/ で行う:
# infrastructure/openai/speech_to_text.py
class SpeechToText:
def transcribe(self, audio: np.ndarray) -> str:
# OpenAI Whisper APIを使った実装
...
# infrastructure/local/speech_to_text.py
class SpeechToText:
def transcribe(self, audio: np.ndarray) -> str:
# FastWhisperを使った実装
...このような構成をとることで、
- STT 実装の切り替え、新しい STT 実装の追加が容易
- テスト時はモックに差し替え可能
になります。
DIコンテナによる依存注入
Spring を使ってきたので、Python でも同じ考え方を実装しました。
# app/di_container.py(抜粋)
from app.infrastructure.local.speech_to_text import SpeechToText as LocalSpeechToText
from app.infrastructure.openai.speech_to_text import SpeechToText as OpenAiSpeechToText
def build_container(config: AppConfig, ...) -> AppContainer:
# 設定に応じてSTT実装を切り替え
if config.stt.provider == "local":
stt = LocalSpeechToText(model=config.stt.local_model)
else:
stt = OpenAiSpeechToText(client=openai_client)
# サービス層に注入
conversation_runner = ConversationRunner(
stt=stt,
conversation_service=conversation_service,
...
)
return AppContainer(...)設定ファイルで STT 実装を切り替え:
# .env
OPENAI_API_KEY=sk-...
OPENAI_MODEL=gpt-4o-mini
# STT実装の切り替え
MY_ENGLISH_BUDDY_STT_PROVIDER=openai # or "local"
# ローカルSTTのモデル(providerがlocalの場合)
MY_ENGLISH_BUDDY_LOCAL_STT_MODEL=distil-large-v3設計パターンについてはまだ勉強中なので、
「ここはこうした方がいい」というアドバイスがあれば教えてください。
でも、お高いんでしょう?
OpenAI の API を使用しているため、どうしても API 利用料金が従量課金されます。 ですが、意外とそうでもないです。 実際に使ってみて、コストを計測しました。
実測値
15-20分の会話で、約15円でした。
30 分/日で計算すると:
| 項目 | 月額 |
|---|---|
| STT (FastWhisper) | 0円(ローカルの場合) |
| Chat (GPT-4o-mini) | 約70-100円 |
| TTS | 約600-800円 |
| 合計 | 約700-900円 |
※1 ドル=150 円で計算
月1000円もかからず毎日30分英会話できます。 しかもオンライン英会話のように時間が決まっていないので、延長も中断も自由です。
工夫した(い)点
音声入力のタイミング判定
最初、ユーザーが話し終わったタイミングをどう判定するかで悩みました。
問題:
- 固定の閾値だと、環境音で誤反応したり、逆に声を拾えなかったりする
- 英語初学者の私は考えている時間が長い
- 考えている間に「話し終わった」と判定されてしまう
解決策:
- 環境音のキャリブレーション
起動時に周囲の環境音を 1 秒間計測し、その音量の 3 倍を閾値として設定します。
# 環境音を計測
noise_level = np.mean(noise_samples)
threshold = noise_level * 3.0- 音量ベースの判定
音量が閾値を超えている間は「話している」とみなし、
閾値を下回って 1.5 秒経過したら「話し終わった」と判定します。
これで、考えている間の小さな声や息継ぎでは終了せず、
自然な会話のリズムが作れるようになりました。
割り込み処理
Buddy が話している途中で、こちらが話し始めることがあります。
普通の会話なら自然なことですが、実装するとなると意外と難しい。
課題:
- 音声出力は即座に止めたい(割り込まれたら黙るべき)
- でも、話していた内容が次の会話のヒントになるかもしれない
例えば:
Buddy: "That's a great question. Let me explain..."
ユーザー: "Wait!"(割り込み)
この"Wait!"は、Buddy が説明しようとしていたことへの反応かもしれない。
解決策:
- 割り込まれたら音声出力を即座に停止
- 生成済みのテキストは少しの間だけ保持
- 次の会話で「さっきこう言おうとしてたけど...」として活用
- 最後まで聞き終わった返答だけを会話記憶に残す
# 割り込まれた内容を一時保存
self._last_interrupted_assistant_text = reply_text
# 次の会話のコンテキストとして使用これで、割り込みがあっても自然な会話の流れを保てるようになりました。
TTSのコストが意外と高かった
事前の計算では「月 100 円くらいかな」と思っていましたが、
実測したら約 600-800 円でした。
原因:
Buddy が毎回「訂正 + 質問」を返すため、1 返答が長くなっています。
平均 120 文字くらい(想定の 2 倍以上)。
今後の対策:
- システムプロンプトで「簡潔に」を強調する
- TTS もローカル化を検討する(品質とのトレードオフ)
コストより品質を取るか、悩ましいところです。
まとめ
「英語を話すまで」が重かった私が、
- 思いついた瞬間に話せる
- 途中でやめてもいい
- 誰にも気を遣わなくていい
そんな、心理的に軽い英語環境を作ることができました。
「英会話アプリを作る」というより、 自分が継続できる環境を設計するという感覚でした。
もし、
- 英会話が続かない
- アプリを開くのすら面倒
- でも英語はできるようになりたい
そんな方がいれば、
英語を話せる友達をデスクトップに住ませるという発想が、少しでも参考になれば嬉しいです。
GitHub
ソースコードはこちら: